Turing Machine

A Turing machine is a theoretical device that manipulates symbols on a strip of tape according to a table of rules. Despite its simplicity, a Turing machine can be adapted to simulate the logic of any computer algorithm, and is particularly useful in explaining the functions of a CPU inside a computer.
The "Turing" machine was described by Alan Turing in 1936,[1] who called it an "a(utomatic)-machine". The Turing machine is not intended as a practical computing technology, but rather as a thought experiment representing a computing machine. Turing machines help computer scientists understand the limits of mechanical computation.
Turing gave a succinct definition of the experiment in his 1948 essay, "Intelligent Machinery". Referring to his 1936 publication, Turing wrote that the Turing machine, here called a Logical Computing Machine, consisted of:
...an infinite memory capacity obtained in the form of an infinite tape marked out into squares, on each of which a symbol could be printed. At any moment there is one symbol in the machine; it is called the scanned symbol. The machine can alter the scanned symbol and its behavior is in part determined by that symbol, but the symbols on the tape elsewhere do not affect the behavior of the machine. However, the tape can be moved back and forth through the machine, this being one of the elementary operations of the machine. Any symbol on the tape may therefore eventually have an innings.[2] (Turing 1948, p. 61)
A Turing machine that is able to simulate any other Turing machine is called a universal Turing machineUTM, or simply a universal machine). A more mathematically-oriented definition with a similar "universal" nature was introduced by Alonzo Church, whose work on lambda calculus intertwined with Turing's in a formal theory of computation known as the Church–Turing thesis. The thesis states that Turing machines indeed capture the informal notion of effective method in logic and mathematics, and provide a precise definition of an algorithm or 'mechanical procedure' (
The Turing machine mathematically models a machine that mechanically operates on a tape. On this tape are symbols which the machine can read and write, one at a time, using a tape head. Operation is fully determined by a finite set of elementary instructions such as "in state 42, if the symbol seen is 0, write a 1; if the symbol seen is 1, shift to the right, and change into state 17; in state 17, if the symbol seen is 0, write a 1 and change to state 6;" etc. In the original article ("On computable numbers, with an application to the Entscheidungsproblem", see also references below), Turing imagines not a mechanism, but a person whom he calls the "computer", who executes these deterministic mechanical rules slavishly (or as Turing puts it, "in a desultory manner").


More precisely, a Turing machine consists of:
- A tape which is divided into cells, one next to the other. Each cell contains a symbol from some finite alphabet. The alphabet contains a special blank symbol (here written as 'B') and one or more other symbols. The tape is assumed to be arbitrarily extendable to the left and to the right, i.e., the Turing machine is always supplied with as much tape as it needs for its computation. Cells that have not been written to before are assumed to be filled with the blank symbol. In some models the tape has a left end marked with a special symbol; the tape extends or is indefinitely extensible to the right.
- A head that can read and write symbols on the tape and move the tape left and right one (and only one) cell at a time. In some models the head moves and the tape is stationary.
- A finite table (occasionally called an action table or transition function) of instructions (usually quintuples [5-tuples] : qiaj→qi1aj1dk, but sometimes 4-tuples) that, given the state(qi) the machine is currently in and the symbol(aj) it is reading on the tape (symbol currently under the head) tells the machine to do the following in sequence (for the 5-tuple models):
- Either erase or write a symbol (instead of aj written aj1), and then
- Move the head (which is described by dk and can have values: 'L' for one step left or 'R' for one step right or 'N' for staying in the same place), and then
- Assume the same or a new state as prescribed (go to state qi1).
- A state register that stores the state of the Turing machine, one of finitely many. There is one special start state with which the state register is initialized. These states, writes Turing, replace the "state of mind" a person performing computations would ordinarily be in.
Note that every part of the machine—its state and symbol-collections—and its actions—printing, erasing and tape motion—is finite, discrete and distinguishable; it is the potentially unlimited amount of tape that gives it an unbounded amount of storage space.
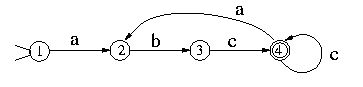
Turing machine "state" diagrams
| Tape symbol | Current state A | Current state B | Current state C | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Write symbol | Move tape | Next state | Write symbol | Move tape | Next state | Write symbol | Move tape | Next state | |
| 0 | P | R | B | P | L | A | P | L | B |
| 1 | P | L | C | P | R | B | P | R | HALT |

To the right: the above TABLE as expressed as a "state transition" diagram.
Usually large TABLES are better left as tables (Booth, p. 74). They are more readily simulated by computer in tabular form (Booth, p. 74). However, certain concepts—e.g. machines with "reset" states and machines with repeating patterns (cf Hill and Peterson p. 244ff)—can be more readily seen when viewed as a drawing.
Whether a drawing represents an improvement on its TABLE must be decided by the reader for the particular context. See Finite state machine for more.

The reader should again be cautioned that such diagrams represent a snapshot of their TABLE frozen in time, not the course ("trajectory") of a computation through time and/or space. While every time the busy beaver machine "runs" it will always follow the same state-trajectory, this is not true for the "copy" machine that can be provided with variable input "parameters".
The diagram "Progress of the computation" shows the 3-state busy beaver's "state" (instruction) progress through its computation from start to finish. On the far right is the Turing "complete configuration" (Kleene "situation", Hopcroft–Ullman "instantaneous description") at each step. If the machine were to be stopped and cleared to blank both the "state register" and entire tape, these "configurations" could be used to rekindle a computation anywhere in its progress (cf Turing (1936) Undecidable pp. 139–140).
It is often said that Turing machines, unlike simpler automata, are as powerful as real machines, and are able to execute any operation that a real program can. What is missed in this statement is that, because a real machine can only be in finitely many configurations, in fact this "real machine" is nothing but a linear bounded automaton. On the other hand, Turing machines are equivalent to machines that have an unlimited amount of storage space for their computations. In fact, Turing machines are not intended to model computers, but rather they are intended to model computation itself; historically, computers, which compute only on their (fixed) internal storage, were developed only later.
There are a number of ways to explain why Turing machines are useful models of real computers:
- Anything a real computer can compute, a Turing machine can also compute. For example: "A Turing machine can simulate any type of subroutine found in programming languages, including recursive procedures and any of the known parameter-passing mechanisms" (Hopcroft and Ullman p. 157). A large enough FSA can also model any real computer, disregarding IO. Thus, a statement about the limitations of Turing machines will also apply to real computers.
- The difference lies only with the ability of a Turing machine to manipulate an unbounded amount of data. However, given a finite amount of time, a Turing machine (like a real machine) can only manipulate a finite amount of data.
- Like a Turing machine, a real machine can have its storage space enlarged as needed, by acquiring more disks or other storage media. If the supply of these runs short, the Turing machine may become less useful as a model. But the fact is that neither Turing machines nor real machines need astronomical amounts of storage space in order to perform useful computation. The processing time required is usually much more of a problem.
- Descriptions of real machine programs using simpler abstract models are often much more complex than descriptions using Turing machines. For example, a Turing machine describing an algorithm may have a few hundred states, while the equivalent deterministic finite automaton on a given real machine has quadrillions. This makes the DFA representation infeasible to analyze.
- Turing machines describe algorithms independent of how much memory they use. There is a limit to the memory possessed by any current machine, but this limit can rise arbitrarily in time. Turing machines allow us to make statements about algorithms which will (theoretically) hold forever, regardless of advances in conventional computing machine architecture.
- Turing machines simplify the statement of algorithms. Algorithms running on Turing-equivalent abstract machines are usually more general than their counterparts running on real machines, because they have arbitrary-precision data types available and never have to deal with unexpected conditions (including, but not limited to, running out of memory).
One way in which Turing machines are a poor model for programs is that many real programs, such as operating systems and word processors, are written to receive unbounded input over time, and therefore do not halt. Turing machines do not model such ongoing computation well (but can still model portions of it, such as individual procedures).
Variants of Turing Machine
In the spring of 1935 Turing as a young Master's student at King's College Cambridge, UK, took on the challenge; he had been stimulated by the lectures of the logician M. H. A. Newman "and learned from them of Gödel's work and the Entscheidungsproblem ... Newman used the word 'mechanical' ... In his obituary of Turing 1955 Newman writes:
To the question 'what is a "mechanical" process?' Turing returned the characteristic answer 'Something that can be done by a machine' and he embarked on the highly congenial task of analysing the general notion of a computing machine.—Gandy, p. 74
Gandy states that:
I suppose, but do not know, that Turing, right from the start of his work, had as his goal a proof of the undecidability of the Entscheidungsproblem. He told me that the 'main idea' of the paper came to him when he was lying in Grantchester meadows in the summer of 1935. The 'main idea' might have either been his analysis of computation or his realization that there was a universal machine, and so a diagonal argument to prove unsolvability.—ibid., p. 76
While Gandy believed that Newman's statement above is "misleading", this opinion is not shared by all. Turing had a life-long interest in machines: "Alan had dreamt of inventing typewriters as a boy; [his mother] Mrs. Turing had a typewriter; and he could well have begun by asking himself what was meant by calling a typewriter 'mechanical'" (Hodges p. 96). While at Princeton pursuing his PhD, Turing built a Boolean-logic multiplier (see below). His PhD thesis, titled "Systems of Logic Based on Ordinals", contains the following definition of "a computable function":
It was stated above that 'a function is effectively calculable if its values can be found by some purely mechanical process'. We may take this statement literally, understanding by a purely mechanical process one which could be carried out by a machine. It is possible to give a mathematical description, in a certain normal form, of the structures of these machines. The development of these ideas leads to the author's definition of a computable function, and to an identification of computability with effective calculability. It is not difficult, though somewhat laborious, to prove that these three definitions [the 3rd is the λ-calculus] are equivalent.—Turing (1939) in The Undecidable, p. 160
When Turing returned to the UK he ultimately became jointly responsible for breaking the German secret codes created by encryption machines called "The Enigma"; he also became involved in the design of the ACE (Automatic Computing Engine), "[Turing's] ACE proposal was effectively self-contained, and its roots lay not in the EDVAC [the USA's initiative], but in his own universal machine" (Hodges p. 318). Arguments still continue concerning the origin and nature of what has been named by Kleene (1952) Turing's Thesis. But what Turing did prove with his computational-machine model appears in his paper On Computable Numbers, With an Application to the Entscheidungsproblem (1937):
[that] the Hilbert Entscheidungsproblem can have no solution ... I propose, therefore to show that there can be no general process for determining whether a given formula U of the functional calculus K is provable, i.e. that there can be no machine which, supplied with any one U of these formulae, will eventually say whether U is provable.—from Turing's paper as reprinted in The Undecidable, p. 145
Turing's example (his second proof): If one is to ask for a general procedure to tell us: "Does this machine ever print 0", the question is "undecidable".
In 1937, while at Princeton working on his PhD thesis, Turing built a digital (Boolean-logic) multiplier from scratch, making his own electromechanical relays (Hodges p. 138). "Alan's task was to embody the logical design of a Turing machine in a network of relay-operated switches ..." (Hodges p. 138). While Turing might have been just curious and experimenting, quite-earnest work in the same direction was going in Germany (Konrad Zuse (1938)), and in the United States (Howard Aiken) and George Stibitz (1937); the fruits of their labors were used by the Axis and Allied military in World War II (cf Hodges p. 298–299). In the early to mid-1950s Hao Wang and Marvin Minsky reduced the Turing machine to a simpler form (a precursor to the Post-Turing machine of Martin Davis); simultaneously European researchers were reducing the new-fangled electronic computer to a computer-like theoretical object equivalent to what was now being called a "Turing machine". In the late 1950s and early 1960s, the coincidentally-parallel developments of Melzak and Lambek (1961), Minsky (1961), and Shepherdson and Sturgis (1961) carried the European work further and reduced the Turing machine to a more friendly, computer-like abstract model called the counter machine; Elgot and Robinson (1964), Hartmanis (1971), Cook and Reckhow (1973) carried this work even further with the register machine and random access machine models—but basically all are just multi-tape Turing machines with an arithmetic-like instruction set.
Today the counter, register and random-access machines and their sire the Turing machine continue to be the models of choice for theorists investigating questions in the theory of computation. In particular, computational complexity theory makes use of the Turing machine:
Depending on the objects one likes to manipulate in the computations (numbers like nonnegative integers or alphanumeric strings), two models have obtained a dominant position in machine-based complexity theory:
- the off-line multitape Turing machine..., which represents the standard model for string-oriented computation, and
- the random access machine (RAM) as introduced by Cook and Reckhow ..., which models the idealized Von Neumann style computer.
—van Emde Boas 1990:4
Only in the related area of analysis of algorithms this role is taken over by the RAM model.—van Emde Boas 1990:16
Hilbert's Problems
Hilbert's problems are a list of twenty-three problems in mathematics published by GermanmathematicianDavid Hilbert in 1900. The problems were all unsolved at the time, and several of them were very influential for 20th century mathematics. Hilbert presented ten of the problems (1, 2, 6, 7, 8, 13, 16, 19, 21 and 22) at the Paris conference of the International Congress of Mathematicians, speaking on 8 August in the Sorbonne. The complete list of 23 problems was later published, most notably in English translation in 1902 by Mary Frances Winston Newson in the Bulletin of the American Mathematical Society.[1]
Hilbert's problems ranged greatly in topic and precision. Some of them are propounded precisely enough to enable a clear affirmative/negative answer, like the 3rd problem (probably the easiest for a nonspecialist to understand and also the first to be solved) or the notorious 8th problem (the Riemann hypothesis). There are other problems (notably the 5th) for which experts have traditionally agreed on a single interpretation and a solution to the accepted interpretation has been given, but for which there remain unsolved problems which are so closely related as to be, perhaps, part of what Hilbert intended. Sometimes Hilbert's statements were not precise enough to specify a particular problem but were suggestive enough so that certain problems of more contemporary origin seem to apply, e.g. most modern number theorists would probably see the 9th problem as referring to the (conjectural) Langlands correspondence on representations of the absolute Galois group of a number field. Still other problems (e.g. the 11th and the 16th) concern what are now flourishing mathematical subdisciplines, like the theories of quadratic forms and real algebraic curves.
There are two problems which are not only unresolved but may in fact be unresolvable by modern standards. The 6th problem concerns the axiomatization of physics, a goal that twentieth century developments of physics (including its recognition as a discipline independent from mathematics) seem to render both more remote and less important than in Hilbert's time. Also, the 4th problem concerns the foundations of geometry, in a manner which is now generally judged to be too vague to enable a definitive answer.
Remarkably, the other twenty-one problems have all received significant attention, and late into the twentieth century work on these problems was still considered to be of the greatest importance. Notably, Paul CohenFields Medal during 1966 for his work on the first problem, and the negative solution of the tenth problem during 1970 by Matiyasevich (completing work of Davis, Putnam and Robinson) generated similar acclaim. Aspects of these problems are still of great interest today. received the
Several of the Hilbert problems have been resolved (or arguably resolved) in ways that would have been profoundly surprising, and even disturbing, to Hilbert himself. Following Frege and Russell, Hilbert sought to define mathematics logically using the method of formal systems, i.e., finitistic proofs from an agreed-upon set of axioms.[2] One of the main goals of Hilbert's program was a finitistic proof of the consistency of the axioms of arithmetic: that is his second problem.[3]
However, Gödel's second incompleteness theorem gives a precise sense in which such a finitistic proof of the consistency of arithmetic is provably impossible. Hilbert lived for 12 years after Gödel's theorem, but he does not seem to have written any formal response to Gödel's work.[4][5] But doubtless the significance of Gödel's work to mathematics as a whole (and not just to formal logic) was amply and dramatically illustrated by its applicability to one of Hilbert's problems.
Hilbert's tenth problem does not ask whether there exists an algorithm for deciding the solvability of Diophantine equations, but rather asks for the construction of such an algorithm: "to devise a process according to which it can be determined in a finite number of operations whether the equation is solvable in rational integers." That this problem was solved by showing that there cannot be any such algorithm would presumably have been very surprising to him.
In discussing his opinion that every mathematical problem should have a solution, Hilbert allows for the possibility that the solution could be a proof that the original problem is impossible.[6] Famously, he stated that the point is to know one way or the other what the solution is, and he believed that we always can know this, that in mathematics there is not any "ignorabimus" (statement that the truth can never be known).[7] It seems unclear whether he would have regarded the solution of the tenth problem as an instance of ignorabimus: what we are proving not to exist is not the integer solution, but (in a certain sense) our own ability to discern whether a solution exists.
On the other hand, the status of the first and second problems is even more complicated: there is not any clear mathematical consensus as to whether the results of Gödel (in the case of the second problem), or Gödel and Cohen (in the case of the first problem) give definitive negative solutions or not, since these solutions apply to a certain formalization of the problems, a formalization which is quite reasonable but is not necessarily the only possible one.[8]
Since 1900, other mathematicians and mathematical organizations have announced problem lists, but, with few exceptions, these collections have not had nearly as much influence nor generated as much work as Hilbert's problems.
One of the exceptions is furnished by three conjectures made by André Weil during the late 1940s (the Weil conjectures). In the fields of algebraic geometry, number theory and the links between the two, the Weil conjectures were very important[citation needed]. The first of the Weil conjectures was proved by Bernard Dwork, and a completely different proof of the first two conjectures via l-adic cohomology was given by Alexander Grothendieck. The last and deepest of the Weil conjectures (an analogue of the Riemann hypothesis) was proven by Pierre Deligne in what some[who?] argue[citation needed] as one of the greatest mathematical achievements of all time. Both Grothendieck and Deligne were awarded the Fields medal. However, the Weil conjectures in their scope are more like a single Hilbert problem, and Weil never intended them as a programme for all mathematics. This is somewhat ironic, since arguably Weil was the mathematician of the 1940s and 1950s who best played the Hilbert role, being conversant with nearly all areas of (theoretical) mathematics and having been important in the development of many of them.
Paul Erdős is legendary for having posed hundreds, if not thousands, of mathematical problems, many of them profound. Erdős often offered monetary rewards; the size of the reward depended on the perceived difficulty of the problem.
The end of the millennium, being also the centennial of Hilbert's announcement of his problems, was a natural occasion to propose "a new set of Hilbert problems." Several mathematicians accepted the challenge, notably Fields Medalist Steve Smale, who responded to a request of Vladimir Arnold by proposing a list of 18 problems. Smale's problems have thus far not received much attention from the media, and it is unclear how much serious attention they are getting from the mathematical community.
At least in the mainstream media, the de facto 21st century analogue of Hilbert's problems is the list of seven Millennium Prize Problems chosen during 2000 by the Clay Mathematics Institute. Unlike the Hilbert problems, where the primary award was the admiration of Hilbert in particular and mathematicians in general, each prize problem includes a million dollar bounty. As with the Hilbert problems, one of the prize problems (the Poincaré conjecture) was solved relatively soon after the problems were announced.
Noteworthy for its appearance on the list of Hilbert problems, Smale's list and the list of Millennium Prize Problems — and even, in its geometric guise, in the Weil Conjectures — is the Riemann hypothesis. Notwithstanding some famous recent assaults from major mathematicians of our day, many experts believe that the Riemann hypothesis will be included in problem lists for centuries yet. Hilbert himself declared: "If I were to awaken after having slept for a thousand years, my first question would be: has the Riemann hypothesis been proven?"[10]
During 2008, DARPA announced its own list of 23 problems which it hoped could cause major mathematical breakthroughs, "thereby strengthening the scientific and technological capabilities of DoD"
| Problem | Brief explanation | Status | Year Solved |
|---|---|---|---|
| 1st | The continuum hypothesis (that is, there is no set whose cardinality is strictly between that of the integers and that of the real numbers) | Proven to be impossible to prove or disprove within the Zermelo–Fraenkel set theory with or without the Axiom of Choice (provided the Zermelo–Fraenkel set theory with or without the Axiom of Choice is consistent, i.e., contains no two theorems such that one is a negation of the other). There is no consensus on whether this is a solution to the problem. | 1963 |
| 2nd | Prove that the axioms of arithmetic are consistent. | There is no consensus on whether results of Gödel and Gentzen give a solution to the problem as stated by Hilbert. Gödel's second incompleteness theorem, proved in 1931, shows that no proof of its consistency can be carried out within arithmetic itself. Gentzen proved in 1936 that the consistency of arithmetic follows from the well-foundedness of the ordinal ε0. | 1936? |
| 3rd | Given any two polyhedra of equal volume, is it always possible to cut the first into finitely many polyhedral pieces which can be reassembled to yield the second? | Resolved. Result: no, proved using Dehn invariants. | 1900 |
| 4th | Construct all metrics where lines are geodesics. | Too vague to be stated resolved or not.[n 1] | – |
| 5th | Are continuous groups automatically differential groups? | Resolved by Andrew Gleason, depending on how the original statement is interpreted. If, however, it is understood as an equivalent of the Hilbert–Smith conjecture, it is still unsolved. | 1953? |
| 6th | Axiomatize all of physics | Unresolved. [n 2] | – |
| 7th | Is a b transcendental, for algebraic a ≠ 0,1 and irrational algebraic b ? | Resolved. Result: yes, illustrated by Gelfond's theorem or the Gelfond–Schneider theorem. | 1935 |
| 8th | The Riemann hypothesis ("the real part of any non-trivial zero of the Riemann zeta function is ½") and other prime number problems, among them Goldbach's conjecture and the twin prime conjecture | Unresolved. | – |
| 9th | Find most general law of the reciprocity theorem in any algebraic number field | Partially resolved.[n 3] | – |
| 10th | Find an algorithm to determine whether a given polynomial Diophantine equation with integer coefficients has an integer solution. | Resolved. Result: impossible, Matiyasevich's theorem implies that there is no such algorithm. | 1970 |
| 11th | Solving quadratic forms with algebraic numerical coefficients. | Partially resolved.[citation needed] | – |
| 12th | Extend the Kronecker–Weber theorem on abelian extensions of the rational numbers to any base number field. | Unresolved. | – |
| 13th | Solve all 7-th degree equations using continuous functions of two parameters. | Resolved. The problem was solved affirmatively by Vladimir Arnold based on work by Andrei Kolmogorov. [n 5] | 1957 |
| 14th | Is the ring of invariants of an algebraic group acting on a polynomial ring always finitely generated? | Resolved. Result: no, counterexample was constructed by Masayoshi Nagata. | 1959 |
| 15th | Rigorous foundation of Schubert's enumerative calculus. | Partially resolved.[citation needed] | – |
| 16th | Describe relative positions of ovals originating from a real algebraic curve and as limit cycles of a polynomial vector field on the plane. | Unresolved. | – |
| 17th | Expression of definite rational function as quotient of sums of squares | Resolved. Result: An upper limit was established for the number of square terms necessary.[citation needed] | 1927 |
| 18th | (a) Is there a polyhedron which admits only an anisohedral tiling in three dimensions? (b) What is the densest sphere packing? | (a) Resolved. Result: yes (by Karl Reinhardt). (b) Resolved by computer-assisted proof. Result: cubic close packing and hexagonal close packing, both of which have a density of approximately 74%.[n 6] | (a) 1928 (b) 1998 |
| 19th | Are the solutions of Lagrangians always analytic? | Resolved. Result: yes, proven by Ennio de Giorgi and, independently and using different methods, by John Forbes Nash. | 1957 |
| 20th | Do all variational problems with certain boundary conditions have solutions? | Resolved. A significant topic of research throughout the 20th century, culminating in solutions[citation needed] for the non-linear case. | – |
| 21st | Proof of the existence of linear differential equations having a prescribed monodromic group | Resolved. Result: Yes or no, depending on more exact formulations of the problem.[citation needed] | – |
| 22nd | Uniformization of analytic relations by means of automorphic functions | Resolved.[citation needed] | – |
| 23rd | Further development of the calculus of variations |